En la teoría he leído de muchas estregias posibles, muchas son definidas y otras personalizadas, y la que nunca me había surgido implementar es la de “Ramas por entorno”, aunque cuando la implementé, la fui personalizando para poder mantener, lo mejor posible, las estrategias de desarrollo que se utilizaban en el proyecto y fue mutando a medida que pasaba el tiempo (para poder lograr la integración y entrega continua).
Entré 2 años desde que comenzó el proyecto, si hubiesen usado GIT, la historia hubiese sido otra.
A continuación haré una pequeña introducción a algunas estrategias conocidas y luego a la que terminé utilizando para trabajar en un complejo y gran proyecto (ya que las anteriores probadas y otros mixes, no me dieron resultado).
Comunmente se utiliza la estrategia de “mainline” (línea principal), donde la rama principal es la encargada de contener el código “stable” de la versión actual del proyecto y marcado por “tags” las versiones que fueron agregandose (merge-commit) y de ella derivan ramas temporales para bugfixing (mantenimiento y bugs) y ramas temporales de desarrollo.
En la práctica es la estrategia más común y tiene como ventaja:
-Pocas ramas
-Menos merge
-Detección rápida de errores
-Menos bugs
-Facilidad para integrar y versionar
-Permite la Integración Continua limpia
-Feedback y status rápido
Aunque por desventaja también podemos decir que:
-Pensar que tenemos una línea estable y que es una versión realmente estable (si no hay mecanismos de TDD o Testing aceitado, esto nunca ocurrirá)
-Para los desarrolladores en grandes equipos es un dolor de cabeza, deben continuamente subir y bajar código de los cambios de otros desarrolladores.
-Cuando se trabaja de esta forma es común quitar o ocultar funcionalidad (con switchs, variables o banderas), lo que puede generar un código sucio o que queda obsoleto y luego nadie retoma o elimina.
-Si hay integración continua y/o entrega continua, el equipo debe estar constantemente verificando el código y esperando que se corrijan los errores de build del resto del equipo.
Otros toman por opción el branching por release o por feature.
En estos casos podemos decir que son similares, ya que ambos intentan congelar la versión a implementar y/o los nuevos desarrollos en ramas paralelas y luego integrar (muchas ramas y en algunos casos aparecen las ramas de fixes de releases o de features y hace más extenso el merging).
Esta estrategia es útil si se define con planificación las caracteristicas a versionar (requiere alta planificación y predefinición de entregas), por lo cual funcionaría si se utlizan metodologías ágiles para el desarrollo, aunque algunos creen que las utilizan pero sigue ocurriendo que no se aplica como corresponde.
Esto hace que sea un gran dolor de cabeza si no se definen sprints correctamente, si no se versiona la funcionalidad o si no se trabaja sobre los bugfixes primero antes que desarrollar sobre código que necesita ajustarse. Con lo cual, la integración y el deploy continuo, se hace sumamente complejo y exagerado en cantidad (ni hablar del testing!).
Y aquí es la parte en la que podes sentirte identificado si es un proyecto con más de 30 personas trabajando, existen extensas funcionalidades, releases dinámicos, bugfixing paralelo, varias vías de entrega de releases, extrañas metodologías de desarrollo (ninguna en concreto) y mala gestión de testing, entre otras.
Luego de luchar con tratar de imponer una estrategia de branching normal, me vi obligado a cambiar “mi” estrategia de branching, con lo cual obté por la de “branching by environment”.
En este proyecto con varios ambientes preproductivos decidí implementar la estrategia de “branching by environment” (podes googlear los distintos casos que pueden implementarse, tiene algunas cosas en común con la de “branching by Quality”).
“Much like feature and bug-fix branches, environment branches
make it easy for you to separate your in-progress code from your stable
code. Using environment branches and deploying from them means you will
always know exactly what code is running on your servers in each of
your environments.”
“In order to keep your environment branches in sync with the environments, it’s a best practice to only execute a merge into an environment branch at the time you intend to deploy. If you complete a merge without deploying, your environment branch will be out of sync with your actual production environment.”
“Best Practices with Environment Branches:
http://guides.beanstalkapp.com/version-control/branching-best-practices.html#branches-environments“In order to keep your environment branches in sync with the environments, it’s a best practice to only execute a merge into an environment branch at the time you intend to deploy. If you complete a merge without deploying, your environment branch will be out of sync with your actual production environment.”
“Best Practices with Environment Branches:
- Use your repository’s default working branch as your “stable” branch.
- Create a branch for each environment, including staging and production.
- Never merge into an environment branch unless you are ready to deploy to that environment.
- Perform a diff between branches before merging—this can help prevent merging something that wasn’t intended, and can also help with writing release notes.
- Merges should only flow in one direction: first from feature to staging for testing; then from feature to stable once tested; then from stable to production to ship.”
“Pattern: Branch per Environment”
A situation often encountered, especially with software systems being developed for “in-house” use, is the requirement to migrate software into successive different environments. Typically this starts with a development environment (sometimes several different ones, allowing for segregation between work by different teams) and moves on into system test, UAT (user acceptance test) and production environments.
By modelling each environment with a parallel “development” branch in the software repository, it is possible to harness the CM tool to assist with:
- Packaging and deployment of migrations between environments;
- Status accounting of current configuration in each environment;
- Access control to different environments; and
- Traceability of changes as they move through the environments (for instance, so that testers which fixes and features are available for test).
En mi caso particular, fui mutandolo y personalizandolo, para poder abarcar las dificultades de versionado que existían y poder implementar una estrategia de integración y entrega continua.
Qué implica el “branching by environment”?
En 1er lugar debemos crear un branch “stable” o “main” que contenga una versión estable o la 1er versión productiva. Este será el puntapié inicial del branching.Luego desde el branch estable, debemos crear tantos branch hijos de este como ambientes preproductivos tengamos. Luego crearemos un branch “QA” para unificar el versionado de funcionalidades (features) que quieran integrarse. Desde el branch “QA” crearemos tantos branch de features como necesitemos y un branch de fixes para trabajar el bugfixing.
La idea es la siguiente:
-Al necesitar un nuevo desarrollo creamos un brach nuevo (por ejemplo: Feature1) desde el branch QA.
-Si necesitamos hacer bugfixing utilizamos el branch de fixes.
-Al querer probar una versión seleccionamos el código que necesitamos y lo mergeamos a QA. Esto sería una versión de prueba (no versión estable). QA siempre tendrá la versión unificada que quiera a futuro implementarse. En caso de querer quitar funcionalidad, se hace en QA, en caso de querer agregar funcionalidad o fixes, se integran a QA. Luego los branch mergeados de features se eliminan.
-QA se implementa en un ambiente de QA (tener exactamente el código del ambiente permite una entrega continua pura).
-QA se testea y se ajusta a medida que se devuelve el estado del testing (en teoría no deberíamos tener una versión a ajustar, salvo que el desarrollo sea de niveles malos).
-Una vez aprobado QA, se mergea a Stage, ocurre lo mismo que QA y al aprobarse y negociarse la versión se mergea a Stable.
-Lo mismo ocurre con las demás ramas.
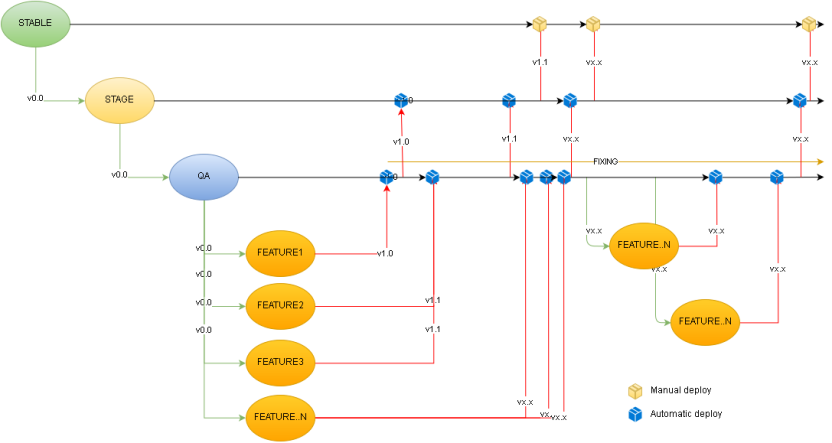
Beneficios:
-Entrega continúa rápida.
-Control de versiones a implementarse.
-Detección temprana de bugs, de mal testing, de mal merge, de mala implementación, de mala planificación.
-Aislamiento y atomización de desarrollos y fixing.
-Centralización de la versión.
-Lo que se implementa es lo que esta en la rama (tener una misma rama en distintos ambientes normalmente hace suponer al equipo que el error es de implementación y no de la relación datos-código).
-Integración y entrega continua pura y aislada.
-Rollback sano (en mi caso nunca me falló y siempre se pudo deshacer y volver a generar la integración sin problemas, desde más de 5 ramas integradas).
-Integración incremental y con posibilidades de integrar desde cualquier rama.
-Entrega a ambientes automatizada y mucho más rápida.
-La subida de código por el equipo queda aislada y no rompe las versiones (algo muy común en otras estrategias). Aunque recae toda la responsabilidad en el encargado de mergear. Si el código de desarrollo no esta bien desarrollado arrastra errores, si el código a integrarse se planifica mal, se integra a funcionalidad que tiene funcionalidad incongruente o que tiene fixes que cambiaron la funcionalidad o fixes que aún no se integraron.
Pero esta estrategia también tiene sus contras, pero eran más leves qué con otra estrategia:
-Mucha flexibilidad, que por un lado es buena, pero por el otro lado es abusiva (se sobre exige la flexibilidad). Se evita frenando solicitudes incongruentes.
-QA recibe muchos bugs y se incrementan si las ramas de features y desarrollos se mantienen durante extenso tiempo (más de 1-2 semanas = mala planificación). Se evita planificando a corto plazo y con sprints o features cortos o en etapas (etapas evolutivas deben ser, es decir, que hasta que una etapa no está estable y productiva, no se continua con la siguiente).
-Si en QA no se atrapan todos los bugs pasan a Stage (aunque existe el beneficio de una etapa más de prueba y fixing). Se evita fixeando en QA y con testing exhaustivo.
-Muchas ramas preproductivas exige más merge o merge extremo. Se evita teniendo un sólo ambiente preproductivo.
-Errores de funcionalidad debido a integraciones que no se solicitan en base al desarrollo continuo (se integra un fix luego de varios desarrollos y rompen o cambian el desarrollo o la funcionalidad original provocando errores funcionales). Se evita con mejor planificación y gestión.
-Si no se integran rapidamente los desarrollos provocan desfase de funcionalidad y desactualización del desarrollo y a veces se solicita mergear código productivo a ramas relegadas o de tiempos excesivos.
-Si se integran fixes y desarrollo con funcionalidad en común modificada, genera más fixing, testing, integración y entrega. Se evita con mejor planificación.
No es el ideal, pero esta estrategia me ha aliviado muchos dolores de cabeza.
Y por último… muchos creen que automatizar la puesta productiva es el ideal… no coincido por experiencia y menos en el caso que les acabo de contar… pero, quizás en un futuro les escriba un post de qué estrategia utilicé para lograrlo.. jeje
Using automatic deployments makes your Production environment very vulnerable. Please don’t do that, always deploy to production manually.
http://guides.beanstalkapp.com/deployments/best-practices.html
Qué recomienda Microsoft para Azure y DevOps?
Creo que me estoy enamorando de Microsoft…

About the author:
Matías Creimerman
I’m a specialist in design, development and management of software solutions with almost 20 years of experience. Microsoft Certificated Professional (MCP). Expert in dot net and Microsoft technologies. Experience and skills in designing solutions in a wide range of commercial, industrial and production areas. Design of architectures, software applications and processes. Skills in leadership and team management. Tech trainer. Technology researcher. Self-taught and dedicated to continuous learning. Skills in estimation, quotation, projects proposals and solutions design. Entrepreneurial spirit. Strong Tech profile but also customer oriented. I perform roles as fullstack dev, tech consultant, technical referent, development leader, team leader, architect, cross leader, tech manager, tech director, trainer, ramp-up & follow-up teams, software factory manager, DevOps and release manager. Regular chess player and musician.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License

|
|
This content is property of Matias Creimerman Any misuse of this material will be punishable This work is licensed under a International Copyright Law protects "original works of authorship" including photographs, videos, and blog posts posted on social media sites The content has no rights to be shared without authorization or citation to the author. This content cannot be sold be adapted or modified partially or totally. All content shared outside this blog that doesn't belong to the author must have citations to the author. |